Hồi quy (regression) là một bài toán kinh điển trong machine learning mà Least Squares (Bình phương Tối tiểu) là một trong những phương pháp phổ biến. Bằng cách xây dựng một model (mô hình) tương quan giữa các biến input và biến mục tiêu từ dữ liệu huấn luyện, chúng ta có thể dự đoán giá trị mục tiêu cho các dữ liệu mới.
Trong bài viết này, chúng ta sẽ tìm hiểu về Least Squares và các phương pháp giải cụ thể và chi tiết cho bài toán này.
Model mà chúng ta hay nghe qua thực chất là một hàm số f(x,θ) với x là một tập hợp các input và θ là một tập hợp các parameter (tham số).
Với mỗi giá trị x, model sẽ cho ra một giá trị y là output tương ứng. y thể là một câu trả lời cho một câu hỏi nào đó, một bức ảnh được tạo ra hay một dự đoán về một sự kiện trong tương lai.
Ma trận
Ma trận (matrix) là một tập hợp các số được sắp xếp thành các hàng và cột. Nó giúp biểu diễn các chiều không gian cao hơn.
Ý nghĩa hình học của ma trận là nó biểu diễn một biến đổi tuyến tính (linear transformation), hay nói cách khác nó giống như một hàm số biến đổi một không gian này sang một không gian khác mà phép biến đổi này có thể là tổ hợp của các phép quay (rotation), co giãn (stretch), trượt (shear),...
Ma trậnA∈Rm×n biểu diễn một phép biến đổi từ không gian Rn sang không gian Rm.
Least Squares
Least Squares là một phương pháp tối ưu hóa để lựa chọn một đường khớp nhất cho một tập hợp các điểm dữ liệu. Đường khớp nhất là đường có tổng bình phương sai số nhỏ nhất giữa các điểm dữ liệu và đường đó.
Nghiệm của bài toán Least Squares là tập hợp giá trị của các parameter ứng với hàm số đã chọn. Từ đó ta sẽ có được một model có thể dự đoán được giá trị output cho một input bất kì.
Công thức
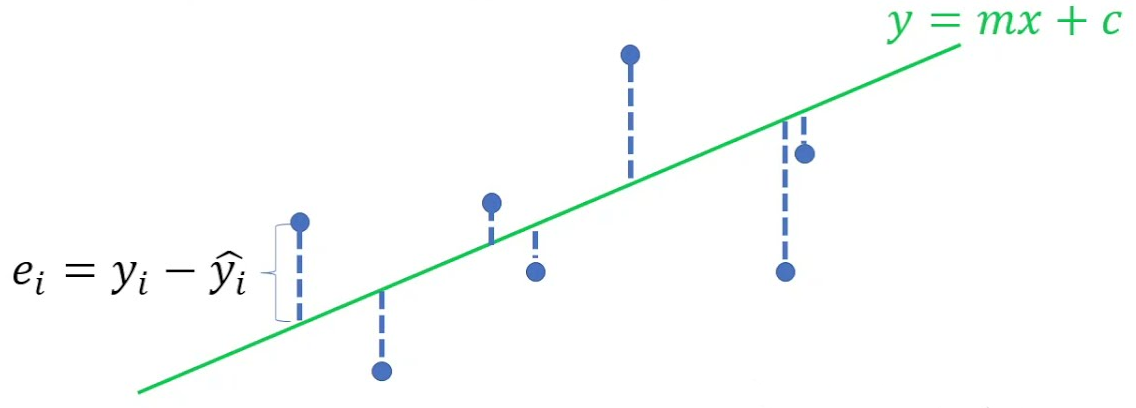
Gọi sự chênh lệch giữa giá trị quan sát được y và giá trị mà model dự đoán y^ là e.
e=y^−y=f(x,θ)−y
Ta có thể tính được tổng bình phương sai số S:
S=i=1∑n(yi^−yi)
Tuy nhiên e có thể nhận giá trị âm, dẫn đến việc không thể so sánh được với các giá trị khác. Vì vậy chúng ta sẽ nâng cấp hàm S như sau:
S=i=1∑n∣yi^−yi∣
Lúc này S đã phản ánh đúng chức năng của việc mô phỏng độ lệch giữa 2 tập giá trị, tuy nhiên hàm trị tuyệt đối ∣x∣ là một hàm không khả vi tại x=0, nên chúng ta không thể dùng nó để tính đạo hàm / gradient. Vì vậy chúng ta sẽ sử dụng hàm bình phương để thay thế cho hàm trị tuyệt đối:
L=21(y^−y)2
Lí do 21 được thêm vào là để đơn giản hóa việc tính đạo hàm / gradient của L: ∇L=y^−y.
Sau khi tìm được nghiệm, chúng ta có thể quan sát được vị trí tương quan giữa các điểm dữ liệu và model.
Source: ProProcessEngineer (YouTube)
Lời giải
Cho f(x,θ) là một model có mparameter: θ={θ0,θ1,…,θm}.
Để S đạt giá trị nhỏ nhất, ta sẽ phải tìm các parameterθ sao cho S đạt cực trị, vì cực trị duy nhất của S sẽ luôn rơi vào trường hợp cực tiểu do đây là tổng của các r2≥0.
Lúc này, ta chỉ cần đặt gradient của S về 0, hay đặt đạo hàm của S về 0 theo từng parameterθ, vì lúc này θ có vai trò như là một biến/ẩn.
Trong đó, A∈Rn×p là một ma trận chứa giá trị của các hàm cơ bản (basic function)ϕ tại các điểm xi đã cho. Và x∈Rp là một vector chứa các parameterai, hay còn gọi là vector hệ số (coefficient vector).
Lưu ý
Hàm cơ bản là một hàm số mà các hàm số khác có thể được biểu diễn dưới dạng tổ hợp tuyến tính (linear combination) của nó. Có nghĩa là ma trậnA có thể biểu diễn được.
Ví dụ: y=θ0sin(x)+θ1cos(x) có thể biểu diễn được bằng ma trậnA=[sin(xi)cos(xi)] với các hàm cơ bản là sin(x) và cos(x). Trong khi đó y=sin(θ0x)+cos(θ1x) không thể biểu diễn được vì các parameterθ0 và θ1 nằm trong hàm số.
Cho trước b∈Rm là một vector chứa các giá trị y quan sát được, lúc này nhiệm vụ của chúng ta là xấp xỉ nghiệm của y theo b với sai số nhỏ nhất:
yAx≈b≈b
Lúc này bài toán trở thành tìm vectorx∈Rn sao cho:
=xmin∣∣y−b∣∣2xmin∣∣Ax−b∣∣2
Tập nghiệm của bài toán này là:
AxATAxxx=b=ATb=(ATA)−1ATb=A†b
Lưu ý
A là ma trận khả nghịch (invertible matrix) khi và chỉ khi A là ma trậnvuông và đủ hạng (full rank). Vì vậy, trong nhiều trường hợp, chúng ta có thể thay thế A−1 bằng A†. Đây là một ma trận giả nghịch (pseudo inverse matrix) được tính bằng (ATA)−1AT, vì ATA luôn khả nghịch (invertible).
Ý nghĩa hình học của ma trận nghịch đảo (inverse matrix) là nếu A biến đổi một không gian nào đó thì A−1 sẽ biến đổi lại về không gian ban đầu. Trong khi đó ma trận giả nghịch sẽ biến đổi về một không gian với các chiều gần giống không gian ban đầu nhất.
Trong trường hợp lí tưởng, khi mà ma trậnAkhả nghịch (vuông và đủ hạng) thì đồng nghĩa với việc phương trình Ax=b có nghiệm duy nhất. Đồng nghĩa với việc tồn tại một đường đi qua tất cả các điểm đã cho.
Tất nhiên, trong mọi trường hợp thì hầu hết thì phương trình trên sẽ vô nghiệm, hay ma trậnA sẽ không khả nghịch. Do đó chúng ta nhờ đến ma trận giả nghịch vì nó sẽ giúp ta xấp xỉ được nghiệm lí tưởng cho bài toán.
Ví dụ
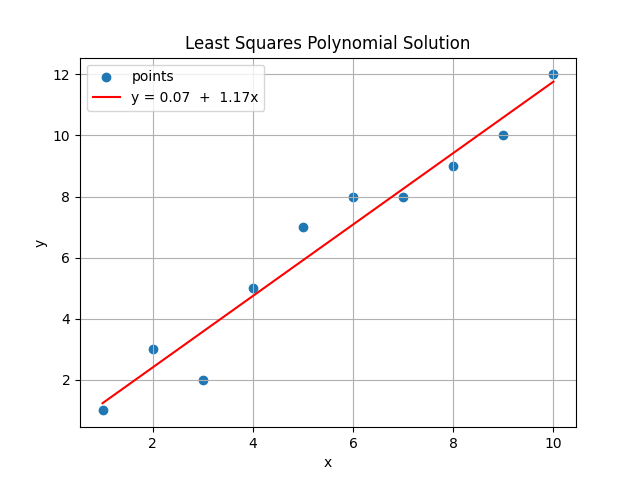
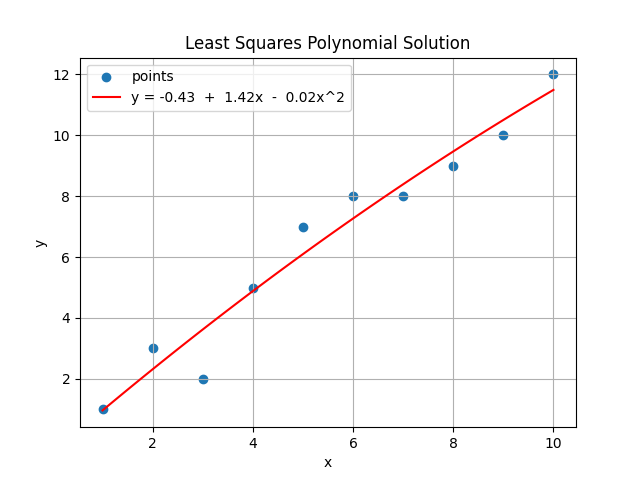
Sử dụng tập dữ liệu ở (4) để xấp xỉ đường thẳng y=θ0+θ1x+θ2x2.
A⟹ATA⟹(ATA)−1⟹(ATA)−1AT⟹(ATA)−1ATb=11⋮112⋮1014⋮100b=13⋮12=1055385553853025385302525333=1.38−0.5250.0417−0.5260.241−0.02080.0417−0.02080.00189=0,9−0,30,020,5−0,130,0080,180,01−0,004−0,050,1−0,011−0,20,16−0,015−0,270,17−0,015−0,250,14−0,011−0,150,07−0,0040,03−0,040,0080,3−0,20,023=−0.431.42−0.02Nghiệm của bài toán là $y = -0.43 + 1.42x - 0.02x^2$